
آیا کامپیوترها می توانند به ما در سنتز مواد جدید کمک کنند؟
آیا کامپیوترها می توانند به ما در سنتز مواد جدید کمک کنند؟ سیستم یادگیری ماشینی الگوهایی را در “دستورالعمل” مواد پیدا می کند، حتی زمانی که داده های آموزشی وجود ندارد.
ماه گذشته، سه دانشمند مواد MIT و همکارانشان مقالهای را منتشر کردند که در آن یک سیستم هوش مصنوعی جدید را توصیف میکرد که میتواند در مقالات علمی نفوذ کند و «دستور العملهایی» را برای تولید انواع خاصی از مواد استخراج کند.
این کار به عنوان اولین گام به سوی سیستمی پیش بینی شد که می تواند دستور العمل هایی را برای موادی که فقط به صورت تئوری توصیف شده اند ایجاد کند.
اکنون، در مقالهای در ژورنال npj Computational Materials ، همان سه دانشمند علم مواد، به همراه یکی از همکارانش در دپارتمان مهندسی برق و علوم کامپیوتر MIT (EECS)، با یک سیستم هوش مصنوعی جدید گامی بیشتر در این مسیر برمیدارند.
می تواند الگوهای سطح بالاتری را که در بین دستور العمل ها سازگار هستند تشخیص دهد.
به عنوان مثال، سیستم جدید قادر به شناسایی همبستگی بین مواد شیمیایی “پیش ساز” مورد استفاده در دستور العمل های مواد و ساختارهای کریستالی محصولات حاصل شد.
معلوم شد که همان همبستگی ها در ادبیات مستند شده است.
این سیستم همچنین بر روشهای آماری متکی است که مکانیسمی طبیعی برای تولید دستور العملهای اصلی ارائه میدهد.
در این مقاله، محققان از این مکانیسم برای پیشنهاد دستور العمل های جایگزین برای مواد شناخته شده استفاده می کنند و پیشنهادات به خوبی با دستور العمل های واقعی مطابقت دارند.
اولین نویسنده مقاله جدید ادوارد کیم، دانشجوی کارشناسی ارشد در رشته علوم و مهندسی مواد است. نویسنده ارشد، مشاور او، السا اولیوتی، استادیار مطالعات انرژی اقیانوس اطلس ریچفیلد در گروه علوم و مهندسی مواد (DMSE) است.
کوین هوانگ، پسادکتر در DMSE، و استفانی جگلکا، استادیار توسعه شغلی کنسرسیوم X-Window در EECS به آنها ملحق شدهاند.
پراکنده و کمیاب

مانند بسیاری از سیستم های هوش مصنوعی با بهترین عملکرد در 10 سال گذشته، سیستم جدید محققان MIT به اصطلاح یک شبکه عصبی است که با تجزیه و تحلیل مجموعه های عظیمی از داده های آموزشی، انجام وظایف محاسباتی را یاد می گیرد.
به طور سنتی، تلاشها برای استفاده از شبکههای عصبی برای تولید دستور العملهای مواد با دو مشکل مواجه شده است که محققان آنها را پراکندگی و کمیاب توصیف میکنند.
هر دستوری برای یک ماده را می توان به عنوان یک بردار نشان داد که اساساً یک رشته طولانی از اعداد است.
هر عدد نشان دهنده یک ویژگی دستور غذا است، مانند غلظت یک ماده شیمیایی خاص، حلالی که در آن حل شده است، یا دمایی که در آن یک واکنش انجام می شود.
از آنجایی که هر دستور غذای داده شده فقط از تعداد کمی از مواد شیمیایی و حلال های فراوانی که در ادبیات توضیح داده شده است استفاده می کند، اکثر آن اعداد صفر خواهند بود.
این همان چیزی است که محققین از «پراکنده» میگویند.
به طور مشابه، برای یادگیری اینکه چگونه تغییر پارامترهای واکنش – مانند غلظتهای شیمیایی و دما – میتواند بر محصولات نهایی تأثیر بگذارد، یک سیستم به طور ایدهآل بر روی تعداد زیادی نمونه آموزش داده میشود که در آن پارامترها متفاوت هستند.
اما برای برخی از مواد – به ویژه موارد جدیدتر – ادبیات ممکن است فقط حاوی چند دستور العمل باشد. این کمیابی است.
کیم میگوید: «مردم فکر میکنند که با یادگیری ماشینی، به دادههای زیادی نیاز دارید، و اگر کم باشد، به دادههای بیشتری نیاز دارید.
وقتی میخواهید روی یک سیستم بسیار خاص تمرکز کنید، جایی که مجبور به استفاده از دادههای با ابعاد بالا هستید اما تعداد زیادی از آنها را ندارید، آیا هنوز هم میتوانید از این تکنیکهای یادگیری ماشین عصبی استفاده کنید؟
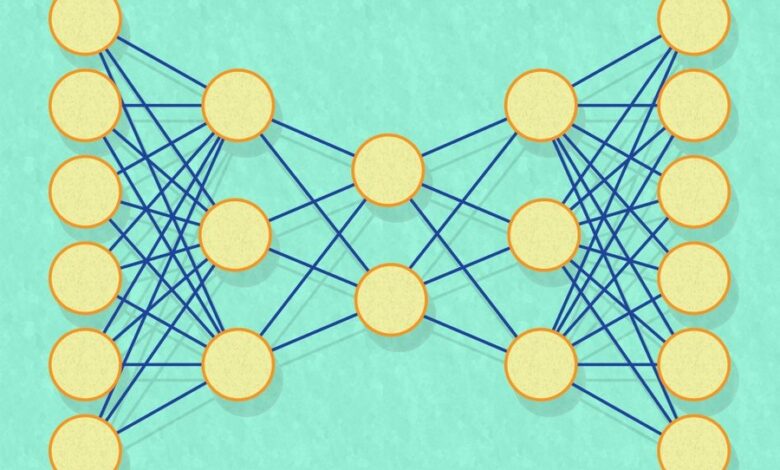
شبکههای عصبی معمولاً در لایههایی مرتب میشوند که هر کدام از هزاران واحد پردازش ساده یا گره تشکیل شدهاند.
هر گره به چندین گره در لایه های بالا و پایین متصل است. داده ها به لایه پایینی وارد می شود، که آن را دستکاری می کند و به لایه بعدی ارسال می کند، که آن را دستکاری می کند و به لایه بعدی می دهد و غیره.
در طول آموزش، اتصالات بین گره ها دائماً تنظیم می شوند تا زمانی که خروجی لایه نهایی به طور مداوم به نتیجه محاسباتی نزدیک شود.
مشکل داده های پراکنده و با ابعاد بالا این است که برای هر مثال آموزشی داده شده، بیشتر گره ها در لایه پایین هیچ داده ای دریافت نمی کنند.
برای اطمینان از اینکه شبکه بهعنوان یک کل دادههای کافی برای یادگیری تعمیمهای قابل اعتماد را میبیند، به یک مجموعه آموزشی بسیار بزرگ نیاز دارد.
آیا کامپیوترها می توانند به ما در سنتز مواد جدید کمک کنند؟
گلوگاه مصنوعی
هدف شبکه محققان MIT تقطیر بردارهای ورودی به بردارهای بسیار کوچکتر است که همه اعداد آنها برای هر ورودی معنادار است.
برای این منظور، شبکه دارای یک لایه میانی است که فقط چند گره در آن وجود دارد – در برخی آزمایشها فقط دو گره.
هدف از آموزش صرفاً پیکربندی شبکه به گونه ای است که خروجی آن تا حد امکان به ورودی آن نزدیک باشد.
اگر آموزش موفقیت آمیز باشد، تعداد انگشت شماری از گره ها در لایه میانی باید به نوعی بیشتر اطلاعات موجود در بردار ورودی را نشان دهند، اما به شکلی بسیار فشرده تر. چنین سیستم هایی که در آنها خروجی تلاش می کند با ورودی مطابقت داشته باشد، “Autoencoder” نامیده می شود.
رمزگذاری خودکار پراکندگی را جبران می کند، اما برای رسیدگی به کمبود، محققان شبکه خود را نه تنها بر روی دستور العمل هایی برای تولید مواد خاص، بلکه در مورد دستور العمل هایی برای تولید مواد بسیار مشابه نیز آموزش دادند.
آنها از سه معیار تشابه استفاده کردند که یکی از آنها به دنبال به حداقل رساندن تعداد تفاوتهای بین مواد است – مثلاً فقط یک اتم را با دیگری جایگزین میکند – در حالی که ساختار کریستالی را حفظ میکند.
در طول تمرین، وزنی که شبکه دستور العمل های نمونه می دهد با توجه به امتیاز شباهت آنها متفاوت است.
بازی شانس
در واقع، شبکه محققان فقط یک رمزگذار خودکار نیست، بلکه چیزی است که رمزگذار خودکار متغیر نامیده می شود.
این بدان معناست که در طول آموزش، شبکه نه تنها از این نظر ارزیابی میشود که خروجیهای آن چقدر با ورودیهایش مطابقت دارند، بلکه همچنین از این نظر که مقادیر دریافتشده توسط لایه میانی چقدر با برخی مدلهای آماری مطابقت دارد – مثلاً منحنی زنگ آشنا، یا توزیع نرمال.
یعنی در کل مجموعه آموزشی، مقادیر دریافت شده توسط لایه میانی باید حول یک مقدار مرکزی جمع شوند و سپس با سرعتی منظم در همه جهات کاهش یابند.
پس از آموزش یک رمزگذار خودکار متغیر با یک لایه میانی دو گره بر روی دستور العمل های دی اکسید منگنز و ترکیبات مربوطه، محققان یک نقشه دو بعدی ساختند که مقادیری را که دو گره میانی برای هر نمونه در مجموعه آموزشی گرفته اند را به تصویر می کشد.
بهطور قابلتوجهی، نمونههای آموزشی که از مواد شیمیایی پیشساز مشابهی استفاده میکردند، به همان مناطق نقشه، با مرزهای واضح بین مناطق، چسبیده بودند.
همین امر در مورد نمونههای آموزشی که چهار شکل از دیاکسید منگنز را تشکیل میدهند، صدق میکند، یا ساختارهای کریستالی. و ترکیب این دو نگاشت همبستگی بین پیش سازهای خاص و ساختارهای کریستالی خاص را نشان داد.
اولیوتی میگوید: «ما فکر میکردیم که این مناطق پیوسته هستند، زیرا دلیلی وجود ندارد که لزوماً درست باشد.»
رمزگذاری خودکار متغیر نیز چیزی است که سیستم محققان را قادر می سازد دستور العمل های جدیدی تولید کند.
از آنجا که مقادیر دریافت شده توسط لایه میانی به یک توزیع احتمال پایبند هستند، انتخاب یک مقدار از آن توزیع به صورت تصادفی احتمالاً دستور العمل قابل قبولی را به دست می دهد.
جگلکا میگوید: «این در واقع به موضوعات مختلفی میپردازد که در حال حاضر علاقه زیادی به یادگیری ماشین دارند.
“یادگیری با اشیاء ساختاریافته، امکان تفسیر توسط متخصصان و تعامل با آنها، و تولید داده های پیچیده ساختار یافته – ما همه اینها را ادغام می کنیم.”
برایس مردیگ، موسس و دانشمند ارشد در Citrine Informatics، شرکتی که دادههای بزرگ و تکنیکهای هوش مصنوعی را ارائه میکند، میگوید: «قابلیت ترکیب» نمونهای از مفهومی است که در علم مواد نقش محوری دارد، اما فاقد توصیف مبتنی بر فیزیک است.
برای انجام تحقیقات علم مواد در نتیجه، صفحههای محاسباتی برای مواد جدید برای سالها به دلیل عدم دسترسی مصنوعی به مواد پیشبینیشده، از بین رفتهاند.
اولیوتی و همکارانش رویکردی جدید و مبتنی بر داده برای تهیه نقشه سنتز مواد اتخاذ کردهاند و سهم مهمی در شناسایی محاسباتی موادی داشتهاند که نه تنها دارای خواص هیجانانگیزی هستند، بلکه میتوانند عملاً در آزمایشگاه نیز ساخته شوند.
این تحقیق توسط بنیاد ملی علوم، شورای تحقیقات علوم طبیعی و مهندسی کانادا، دفتر تحقیقات نیروی دریایی ایالات متحده، ابتکار انرژی MIT و برنامه علوم پایه انرژی وزارت انرژی ایالات متحده حمایت شد.



